










MPEG-4算法非常復雜,其編解碼的實時性難以保證,通常只能實現對中低分辯率視頻的實時編碼。本文基于TI公司的C64x系列DSPs設計并實現了一種MPEG-4編碼器,實現了對D1分辨率(720×576)視頻的實時編碼,且在保證輸出碼率低于1Mbps的同時,解碼圖像具有較高的峰值信噪比和較好的視覺效果。
1 編碼系統的硬件結構
編碼系統以TMS320DM642高性能通用DSP芯片為核心。圖1為系統框圖。
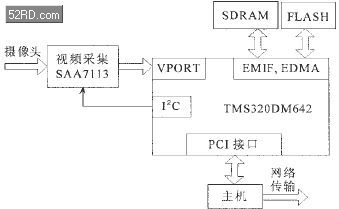
圖1 編碼器系統框圖
1.1 TMS320DM642芯片的特點
DM642屬于TI公司的C64x系列DSPs。Veloci TI結構使C6000 DSPs在視頻和圖像處理中得到廣泛應用。CPU的VLIW結構由多個并行運行的執行單元組成,這些單元在單個周期內可執行多條指令。并行是C6000獲得高性能的關鍵。C64x在C6000的基礎上有一些重要的改進。除了有更高的時鐘頻率外,C64x從以前的Veloci TI結構擴展到Veloci TI.2結構,包含了許多新的指令,增加了額外的數據通道,寄存器的數量也增加了一倍。這些擴展使得CPU可以在一個時鐘周期內處理更多的數據,從而獲得更高的運算性能。
DM642芯片集成了各種片內外設,使得開發視頻和圖像領域的應用更為方便。它帶有三個可配置的視頻端口,提供與視頻輸入、視頻輸出以及碼流輸入的無縫接口。這些視頻端口支持許多格式的視頻輸入/輸出,包括BT.656、HDTV Y/C、RGB以及MPEG-2碼流的輸入。利用DM642開發視頻編碼器,其視頻輸入部分只需要一塊視頻采集芯片即可,如Phillips的SAA7113,無需外加邏輯控制電路和FIFO緩存,使硬件系統更為簡單和穩定。DM642的其它外設包括:10Mbps/100Mbps的以太網口(EMAC)、多通道音頻串口(McASP)、外部存儲器接口(EMIF)、主機接口(HPI)、多通道緩沖串口(McBSP)以及PCI接口等。
1.2 系統工作流程
該編碼系統可分為圖像壓縮卡和主機兩部分。其工作流程如圖2所示。
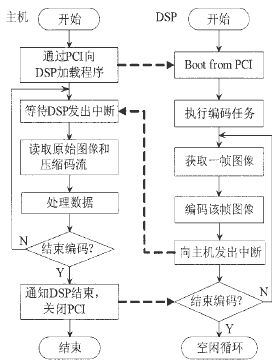
圖2 系統工作流程圖
首先主機通過PCI初始化DSP并對其加載程序;DSP開始運行MPEG-4編碼程序,從視頻端口獲取實時采集的視頻,如圖1所示。SAA7113輸出BT.656格式的數字視頻,作為DM642 VPORT的輸入,VPORT輸出YUV(4:2:0)格式的圖像,作為編碼程序的輸入;DSP完成一幀圖像的編碼,通過PCI向主機發出中斷;主機響應中斷,從DSP的存儲空間讀取原始圖像數據和壓縮后的碼流。主機程序在VC++環境下編寫,提供與用戶交互的界面,可對數據進行各種處理,包括原始視頻的實時播放、保存,壓縮碼流的實時解壓播放、保存、回放、網絡傳輸,從網絡接收壓縮碼流實時解壓回放等。
需要注意的是原始圖像和壓縮碼流在DSP中的存儲。視頻端口、編碼程序和主機都要訪問原始圖像,例如在某一時刻,編碼程序訪問當前幀圖像,主機讀取上一幀圖像,而視頻端口正在輸入下一幀圖像,為了避免訪問沖突,原始圖像在DSP中采用三緩沖區進行管理。壓縮碼流由編碼程序寫入,主機讀取,所以采用乒乓制進行存儲。
1.3 內存分配
DM642片內只有256KB的存儲空間,因此當前幀、參考幀和當前幀的重建幀都必須放至片外存儲器,壓縮碼流若被主機讀取,也放至片外。其它數據如程序代碼、全局變量、VLC碼表、各編碼模塊產生的中間數據等均可放至片內。
由于CPU訪問片外的速度通常要比訪問片內慢幾十倍,片外數據的傳輸通常成為程序運行時的瓶頸,即使代碼效率很高,流水線也會因為等待數據而被嚴重阻塞。解決這一問題的有效方法是用EDMA傳送數據。程序是逐個宏塊進行編碼的,在編碼當前宏塊的同時,EDMA將下一個宏塊的數據、用到的參考幀數據由片外傳送至片內;當前宏塊做完運動補償后,EDMA將重建后的宏塊由片內傳送至片外。這樣CPU只對片內數據進行操作,使得流水線可以順利進行,而壓縮碼流按逐個碼字有時間間隔地寫入,可由CPU直接寫至片外。
2 采用預測技術的運動估計算法
運動估計是MPEG-4編碼中計算量的一部分,占據整個編碼時間的50%以上。各種快速運動估計算法也成為近年來研究的熱點。本文通過實驗證明,采用預測技術的運動估計不但可以大大縮短計算時間,而且也有助于提高圖像的質量。
宏塊(Macro Block)的運動矢量(Motion Vector)在時間和空間都具有相關性,預測的原理就是利用當前幀和參考幀內相鄰位置宏塊的MV來預測當前宏塊的MV。下面詳述本文所采用的預測算法。
(1)確定當前宏塊MV的7個候選值PreMV1~7。
如圖3所示。PreMV1=(0,0);PreMV4取當前宏塊左邊相鄰宏塊的MV值;PreMV5取上邊相鄰宏塊的MV值;PreMV6取右上方相鄰宏塊的MV值;PreMV2=mid{PreMV4, PreMV5, PreMV6},即取三者的中值;PreMV3取參考幀相同位置宏塊的MV值;PreMV7取參考幀右下方相鄰宏塊的MV值。
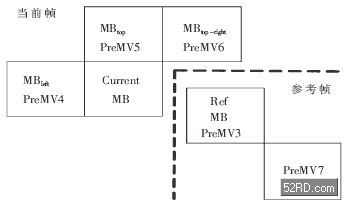
圖3 預測運動矢量示意圖
(2)確定篩選候選值的依據——SAD(誤差和)的門限值ThreshSAD。
SAD是確定匹配塊的準則。門限值ThreshSAD是指這樣一個值:如果參考幀內某一宏塊和當前宏塊的SAD小于ThreshSAD,則當前宏塊的MV值就可取作二者之間的位移。因此,ThreshSAD就可作為篩選7個候選值的依據。
由于SAD在空間上的相關性,ThreshSAD由相鄰宏塊的SAD值來確定:
ThreshSAD=Min{SADleft,SADtop,SADtop_left}
其中,SADleft、SADtop、SADtop-right分別為MBleft、MBtop、MBtop-right和其對應匹配塊的SAD值,ThreshSAD取三者的小值。
(3)從7個候選值中選出當前宏塊的MV值。
按照PreMV1~7的順序,依次計算當前宏塊和7個匹配塊的SAD值。如果有SAD值小于ThreshSAD,即停止計算,選用對應的PreMV作為當前宏塊的MV值;如果7個SAD值均大于ThreshSAD,則采用運動搜索來確定當前宏塊的MV值。該運動搜索并不以MV=(0,0)為中心,而是以對應SAD值小的PreMV為中心,搜索采用簡化的菱形算法。
對標準視頻序列foreman.cif(352×288)進行編碼(碼率300kbps),測得表1所示數據。采用預測的運動估計算法利用視頻序列在時間和空間上的相關性,無需對每個宏塊都進行運動搜索,而且其搜索中心點也同樣利用了相關信息,搜索算法也可進一步簡化,因此大大減少了運動估計的計算量;同時,預測有助于提高圖像質量,直接進行快速運動搜索通常會帶來局部小的問題,從而影響圖像質量,而PreMV1~7取自位于當前宏塊周圍各個方向的宏塊的MV值,避免陷入局部小。
| 采用預測 | 平均每個宏塊所需的 SAD值計算次數 |
峰值信噪比PSNR(dB) | 平均幀率(fps) |
| 是 | 5 | 33.16 | 120 |
| 否 | 15 | 33.23 | 95 |
3 基于C64x CPU的軟件優化技術
為了提高代碼的執行效率,必須充分利用C64x CPU的VLIW和流水線結構對其進行優化,使程序無沖突地并行執行。MPEG-4編碼程序中包含大量的循環體,例如計算SAD值、量化、DCT、半像素插值、運動補償和構建重建幀等。這些循環體代碼并不復雜,但執行次數頻繁,占據了編碼的絕大部分時間,因此循環體的優化是重點。本文所采取的代碼優化分為C語言優化和編寫線性匯編兩個步驟,主要從消除數據相關性、數據打包和循環體的軟件流水三個方面進行優化。
3.1 針對C語言的優化
C代碼的優化主要依靠開發環境CCS的編譯器完成,編程者需要合理選擇編譯選項,并利用特定的關鍵字和指令向編譯器提供優化信息。例如關鍵字restrict用來消除數據間的相關性,編譯器從而可以安排語句的并行執行;內聯函數_nassert有助于數據的打包處理;宏指令#pragma MUST_ITERATE告訴編譯器有關循環迭代次數的信息,編譯器會根據這一信息進行軟件流水。
3.2 用線性匯編改寫關鍵代碼
線性匯編是TMS320C6000特有的一種編程語言,介于語言和匯編語言之間。它可以指定指令用到的寄存器和功能單元,更易于對數據的打包處理。
線性匯編代碼的并行處理和軟件流水由匯編優化器完成,編程者需要熟悉C64x DSP的CPU結構和指令集,認真設計代碼并充分利用編譯器的反饋信息合理修改代碼,才能寫出高質量的線性匯編。本設計中程序主框架采用C語言編寫,其它各關鍵部分的代碼采用線性匯編實現。表2是代碼優化前后的效率對比,表2中所列各代碼段均針對8×8宏塊進行處理。
| 代碼段 | 未優化 | C優化后 | 線性匯編優化后 |
| SAD值計算 | 1400 | 55 | 34 |
| 量化 | 1250 | 238 | 108 |
| 逆量化 | 1200 | 291 | 170 |
| FDCT | 1360 | 292 | 96 |
| IDCT | 1600 | 373 | 102 |
| 半像素插值 | 2800 | 466 | 246 |
| 運動補償、做差 | 1950 | 160 | 59 |
| 重建宏塊 | 1000 | 890 | 88 |
4 結果分析
對各標準視頻序列進行編碼,測得表3所示數據。實時采集D1(720×576)分辨率的視頻進行編碼,測得碼率為850kbps時,編碼速率達25fps以上,峰值信噪比(PSNR)高于31dB,實現了高分辨率的實時MPEG-4編碼。
| 視頻序列 | 分辨率 | 碼率(bps) | PSNR(dB) | 平均幀率(fps) |
| News | QCIF | 100k | 36.23 | 480 |
| Silent | QCIF | 100k | 35.66 | 485 |
| Foreman | QCIF | 100k | 32.04 | 465 |
| Foreman | CIF | 300k | 33.16 | 120 |
表3中各視頻序列的編碼均采用了8×8半像素精度的運動估計,解碼圖像的視覺效果較好。對于較低分辨率的視頻(QCIF、CIF),其編碼速率已遠遠高于實時的要求,因此可以考慮添加新的算法以提高壓縮效率并增強碼流的抗差錯性能。
本文以DM642芯片為例詳述了基于C64x DSPs的MPEG-4實時編碼器設計。編碼器采用MPEG-4 Simple Profile算法,在算法和代碼優化方面還有一定的研究空間。本文給出的設計方法可以進一步推廣到H.264或者其他視頻編碼系統。